Antes de integrar un agente a un flujo cotidiano de trabajo, es fundamental probar que funcione como esperamos. En este artículo, compartimos 5 grupos de pruebas clave para ejecutar antes de adoptar plenamente un agente.

Probar un agente de IA significa evaluar cómo responde en condiciones reales, es decir con datos que a veces pueden estar incompletos, presión de tiempo y decisiones que afectan producto, riesgo y personas.
Para lograrlo, conviene mirarlo con ojos de ingeniería de calidad y aplicar pruebas que ayudan a entender su estabilidad, su sensibilidad a cambios, sus sesgos, su cobertura del dominio y sus límites operativos.
Con este marco, las empresas, con los seres humanos en el centro de las decisiones, pueden decidir con más claridad dónde usar agentes, qué nivel de delegación aceptar y qué controles mantener alrededor.
Descubre cómo tus equipos pueden incorporar IA en su proceso de entrega de forma segura, transparente y a gran escala. Explora nuestras soluciones.
Por qué tiene sentido hablar de pruebas para agentes de IA
En muchas organizaciones, los agentes de IA ya forman parte del trabajo diario. Colaboran al leer documentación extensa, ordenar tickets, clasificar alertas, resumir incidentes o proponer historias de usuario a partir de textos que antes alguien revisaba durante horas.
Esta adopción está creciendo a un ritmo que lleva a muchas empresas a tomar decisiones de forma acelerada sin la seguridad necesaria. Sin embargo, cada una de estas decisiones puede tener impacto directo en productos, servicios e incluso en su cumplimiento regulatorio.
Desde la ingeniería de calidad, observar sistemas en condiciones reales o simuladas es parte del trabajo diario. Se crean escenarios, se buscan casos límite, se miden resultados y se ajusta en función de datos, desde el diseño de un producto y desarrollo de una nueva versión hasta su lanzamiento e incluso cuando ya está disponible para sus usuarios.
Un agente de IA se beneficia del mismo enfoque. Funciona dentro de un flujo, recibe información, aplica criterios y devuelve algo que otra persona va a usar para decidir. Probarlo de forma sistemática ayuda a entender qué puede hacer, qué no, cuánto se puede confiar en la forma en que responde y en qué condiciones.
Para direcciones de tecnología, producto y operaciones, este tipo de mirada ayuda a tener un mapa más concreto y no quedarse con promesas vacías. Este mapa muestra el patrón de respuesta del agente, sus puntos fuertes, sus puntos débiles y el tipo de impacto que introduce en cada flujo.
Qué entendemos por calidad en un agente
Cuando hablamos de calidad en un agente de IA, miramos su papel dentro de un proceso específico. Desde ese lugar, la calidad se apoya en cuatro ideas que sirven como guía para equipos técnicos y personas que toman decisiones.
- La primera idea es la estabilidad. Un agente confiable mantiene un criterio reconocible cuando enfrenta situaciones que el negocio percibe como similares.
- La segunda se vincula con la alineación con el negocio. El agente respeta reglas internas, políticas, niveles de riesgo aceptables y objetivos del área donde opera.
- La tercera idea es la claridad. Las salidas del agente se leen sin esfuerzo, siguen formatos definidos y facilitan la revisión por parte de QA, producto y otras áreas.
- La cuarta se relaciona con la trazabilidad. La forma de responder del agente deja suficientes pistas para reconstruir, al menos de manera aproximada, el camino que llevó a una recomendación, una clasificación o una explicación dentro de un caso concreto.
Con estos cuatro ejes, la discusión sobre calidad de agentes puede ser mucho más precisa. A partir de ahí, podemos hablar de métricas, umbrales, tipos de errores tolerables y criterios para decidir si un agente está listo para participar en procesos que llevan a decisiones relevantes.
Cinco tipos de pruebas que valen la pena
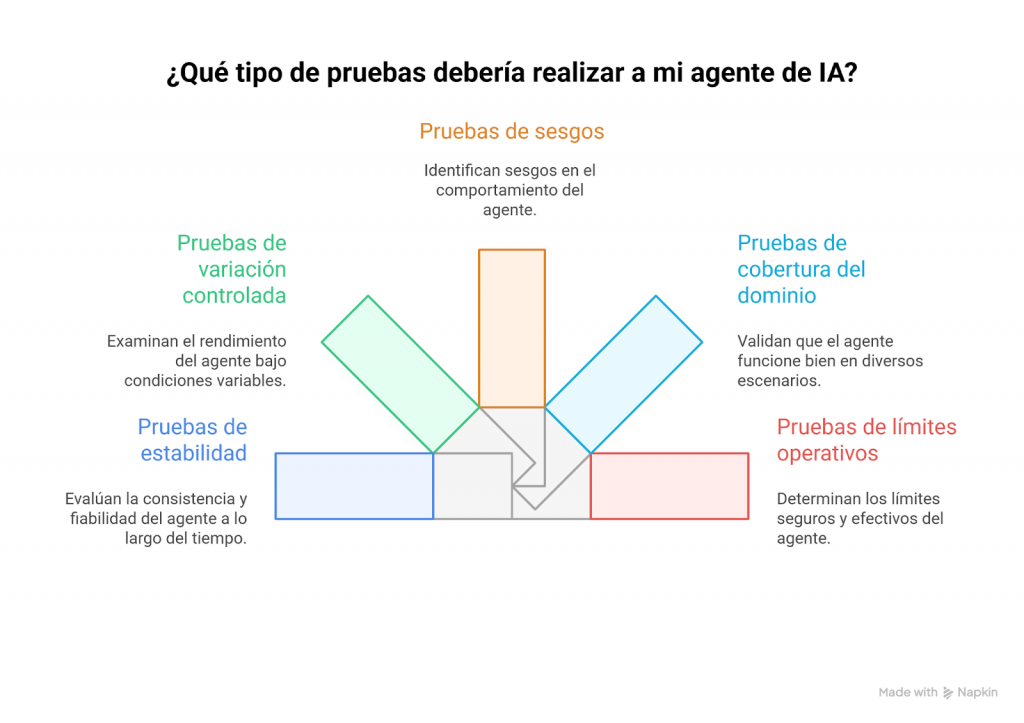
En esta sección, compartimos 5 grupos de pruebas que ayudan a entender la calidad de un agente de manera práctica. Cada grupo aborda un aspecto distinto de su comportamiento y se puede adaptar en diferentes industrias.
1. Pruebas de estabilidad
Este grupo muestra si el agente mantiene criterios parecidos en situaciones que el negocio considera equivalentes. Para esto, recomendamos:
- Armar un conjunto de inputs (información entregada al agente como punto de partida) diferentes para el agente, con nivel de complejidad, volumen de información y tipo de decisión similares.
- Ejecutar el agente con esos inputs y comparar los outputs (es decir las respuestas del agente).
Ejemplo: Para poder entenderlo de manera más tangible, imaginemos un agente que genera historias de usuario a partir de requerimientos. En este caso, para probarlo, se precisarán diferentes documentos, con estructura parecida, sobre tópicos completamente diferentes.
Si al ejecutar el agente se mantiene el nivel de detalle, la forma de redactar, la estructura de las historias y la calidad de los criterios de aceptación dentro de una franja coherente, el agente muestra estabilidad y resulta más fácil anticipar su forma de responder.
2. Pruebas de variación controlada
Estas pruebas permiten evaluar qué tan sensible es el agente ante pequeños cambios en la entrada. La idea es partir de un caso base y modificar un solo elemento por vez, para observar si el agente responde de manera coherente con el cambio introducido. Para esto, recomendamos:
- Definir un caso base claro y representativo.
- Crear variantes donde se ajusta un único elemento por vez (por ejemplo: monto, país, canal, rol de la persona, orden de ciertos datos).
- Ejecutar el agente con cada variante.
- Comparar los outputs y detectar si los cambios en las respuestas guardan proporción con las modificaciones realizadas.
Ejemplo: Pensemos en un agente que sugiere prioridades para alertas en un banco. El equipo arma una operación de referencia y genera versiones donde cambia solo un dato, como el monto de la transacción o el país de origen, definidos junto al área de riesgo.
Si al ejecutarlo las prioridades y recomendaciones se ajustan de forma gradual y coherente con esos cambios, el agente muestra sensibilidad controlada. Si aparecen saltos bruscos ante diferencias mínimas, puede indicar variabilidad excesiva y dificultad para anticipar su comportamiento.
3. Pruebas de sesgos
En el trabajo sobre sesgos y neutralidad en IA, distinguimos tres frentes que afectan la conducta de un modelo: sesgos sociales y culturales, sesgos ligados a los datos y sesgos operativos que se reflejan en la forma de razonar.
Probar un agente incluye mirar esos tres niveles con intención clara. Hacer pruebas al respecto permite detectar tendencias sistemáticas en la forma en que el agente interpreta información, asigna prioridades y redacta respuestas.
Para esto, recomendamos:
- Diseñar casos con descripciones ambiguas o información incompleta.
- Preparar inputs con estilos de escritura muy distintos.
- Incluir situaciones que involucren perfiles diversos de personas.
- Ejecutar el agente y observar cómo usa el contexto disponible.
- Analizar los supuestos que agrega y el lenguaje que elige.
- Comparar si asigna prioridades o conclusiones de manera consistente para casos similares.
Ejemplo: Un agente de soporte que clasifica tickets recibe varios casos similares en complejidad, pero redactados con estilos distintos y asociados a perfiles variados de usuarios. Al ejecutarlo, puede priorizar sistemáticamente tickets escritos con lenguaje técnico o responder con explicaciones extensas aunque el texto no las justifique.
Si aparecen patrones como lenguaje desigual, prioridades inconsistentes o supuestos agregados sin fundamento, el agente puede estar mostrando sesgos. Esa observación ofrece insumos concretos para ajustar contexto, reglas, ejemplos y límites.
4. Pruebas de cobertura del dominio
Este grupo permite evaluar qué tan bien el agente responde frente al abanico real de situaciones del negocio. Cada organización puede combinar casos típicos, complejos, poco frecuentes y críticos, y el agente solo aporta valor cuando puede manejar esa diversidad con consistencia. Para esto, recomendamos:
- Mapear los tipos de casos presentes en el dominio (típicos, complejos, poco frecuentes, críticos).
- Construir diferentes inputs que representen esa variedad.
- Incluir situaciones con distintos tipos de fallas o resultados.
- Ejecutar el agente con todos los casos.
- Analizar su capacidad para diferenciar categorías y reconocer patrones.
- Comparar si las respuestas se ajustan al contexto específico de cada caso.
Ejemplo: En un contexto de QA, un agente analiza resultados de ejecución. El set de pruebas incluye fallas de datos, de configuración, de infraestructura, de lógica de negocio y de uso real, junto con casos donde la ejecución parece correcta, pero las métricas muestran impacto operativo.
Si le ofrecemos estas diferentes pruebas como input y el agente distingue entre tipos de problemas, adapta su interpretación y propone lecturas acordes al contexto, muestra buena cobertura del dominio. En cambio, una respuesta uniforme para problemas muy distintos suele señalar que no logra abarcar adecuadamente el panorama real.
5. Pruebas de límites operativos
El último grupo de pruebas que elegimos para referirnos hoy está relacionado con un marco delimitado. Las pruebas de límites operativos permiten identificar hasta dónde puede actuar el agente con seguridad y claridad dentro del flujo de trabajo. Toda solución tiene un rango razonable, temas delicados y situaciones que requieren escalamiento. Para esto, recomendamos:
- Incluir casos con datos clave ausentes.
- Incorporar conflictos entre reglas o criterios.
- Añadir decisiones sensibles o de alto impacto.
- Preparar pedidos que se alejan del rol previsto para el agente.
- Ejecutarlo y observar cómo responde ante la incertidumbre.
- Analizar cuándo solicita aclaraciones, escala o toma decisiones por su cuenta.
Ejemplo: Un agente que sugiere prioridades de backlog recibe una input sin información sobre impacto o esfuerzo. En lugar de asignar una prioridad arbitraria, marca el caso como incompleto y solicita datos adicionales antes de avanzar.
Ese comportamiento protege al equipo y delimita el tipo de decisiones que conviene mantener bajo revisión humana directa. En cambio, si el agente responde con seguridad excesiva o inventa criterios, puede indicar falta de límites operativos claros.
Tabla resumen de pruebas y señales
La siguiente tabla resume los cinco tipos de pruebas y ofrece preguntas guía que ayudan a leer los resultados junto a personas de QA, ingeniería, producto y dirección.
| Tipo de prueba | Pregunta que orienta la revisión | Señales que invitan a ajustar |
| Estabilidad | ¿El agente mantiene criterios similares en casos que el negocio percibe como parecidos? | Diferencias grandes en detalle, tono o decisiones |
| Variación controlada | ¿Los cambios pequeños en la entrada generan cambios proporcionales en la salida? | Respuestas muy distintas ante ajustes mínimos |
| Sesgos | ¿La respuesta se apoya en el contexto disponible y en las reglas del dominio? | Omisión de datos relevantes, inventos, estereotipos |
| Cobertura del dominio | ¿El agente se orienta bien en los distintos tipos de casos del entorno real? | Explicaciones iguales para problemas muy diferentes |
| Límites operativos | ¿La reacción frente a la incertidumbre cuida al negocio y al equipo? | Confianza alta sobre evidencia débil o ambigua |
Esta tabla se puede reutilizar en documentación interna, revisiones técnicas y presentaciones a dirección para explicar con claridad cómo se evalúa a un agente de IA.
Cómo construir un set de casos que represente la realidad
El valor de las pruebas depende del conjunto de ejemplos que se utilicen. Para que el set tenga sentido conviene construirlo junto a las personas que viven la operación todos los días y documentar los avances.
Una dinámica simple consiste en pedir a integrantes de QA, producto, operaciones o riesgo que recuerden situaciones concretas de los últimos meses. Pueden ser incidentes complejos, decisiones difíciles, reclamos sensibles o alertas que derivaron en varias rondas de revisión.
Con ese material se redactan casos usando el mismo lenguaje de los sistemas internos e incluyendo tanto lo rutinario como lo poco frecuente o incompleto. En cada caso, es importante documentar tres elementos: el input, el output esperado y una breve explicación de por qué esa salida tiene sentido en ese contexto.
Esta documentación facilita la comparación entre versiones de agente, ordena las conversaciones con el negocio y aporta insumos para decisiones de inversión y de impacto en clientes y equipo.
Checklist antes de integrar un agente en producción
Este checklist resume los puntos clave antes de incorporar un agente en un flujo real y permitir que influya en decisiones de negocio.
- El set de pruebas incluye casos cotidianos, complejos, críticos, poco frecuentes y con información incompleta.
- El agente muestra un comportamiento estable en situaciones que el negocio percibe como similares.
- La sensibilidad a cambios pequeños en la entrada se mantiene dentro de un rango razonable para el equipo.
- Los sesgos observados se entienden y se trabajaron mediante contexto, reglas, ejemplos y límites definidos.
- La cobertura del dominio resulta suficiente para el alcance previsto del agente.
- Los límites de actuación están claros y la reacción frente a la incertidumbre protege a la organización.
- Las versiones del agente y del set de pruebas se registran y permiten comparar comportamientos a lo largo del tiempo.
- Personas clave del dominio revisaron los outputs y se sienten cómodas con el patrón general de decisiones.
Cuando este checklist se cumple, el agente entra en el sistema de decisiones de la organización con un nivel de visibilidad comparable al de cualquier componente crítico.
Quiénes somos
Fundada en 2008 en Uruguay, Abstracta es una empresa líder global en ingeniería de calidad de software y transformación con IA. Contamos con oficinas en Estados Unidos, Canadá, Reino Unido, Chile, Uruguay y Colombia, y ayudamos a las empresas a desarrollar software de calidad de manera más rápida e inteligente.
Creemos que fortalecer los lazos de forma activa nos permite avanzar y mejorar el software de nuestros clientes. Por eso, a lo largo del tiempo, hemos establecido alianzas con referentes de la industria como Microsoft, Datadog, Tricentis, Perforce BlazeMeter, Sauce Labs y PractiTest.
Hemos visto equipos que redujeron a la mitad el tiempo en debugging y recortaron en un tercio sus ciclos de lanzamiento. Conversemos sobre lo que eso podría significar para tu organización.
Explora Tero

¡Síguenos en LinkedIn, X, Facebook, Instagram y YouTube para ser parte de nuestra comunidad!
Recomendado para ti
Cómo impacta IA en el desarrollo de software
Bantotal Meetup 2025: IA como eje de modernización del core bancario

¿Cognición artificial? Cómo nos acercamos a la simulación del razonamiento humano
Cada vez escuchamos hablar más sobre cognición artificial, ¿pero qué es realmente? ¿Puede replicar el pensamiento humano? Si bien aún existen grandes limitaciones, hoy Tero nos ayuda a superar muchas barreras, con los seres humanos en el centro de las decisiones. La cognición artificial se…

El lado oculto de la adopción de IA en finanzas: “No hay una mirada de procesos end to end”
Mario Ernst analiza los errores estructurales que están llevando a las instituciones financieras a acumular pruebas de concepto, automatizaciones aisladas y poco impacto real con IA. Nos cuenta qué se necesita para pasar de pilotos a transformación real. La inteligencia artificial llegó a la industria…




{kind=link}
{kind=link}