¿Alguna vez pensaste si el modelo de la pirámide de automatización es aplicable también para optimizar la estrategia de testing de performance? En este artículo, compartimos una mirada innovadora, “la pirámide de automatización para pruebas de performance”, un modelo que creamos a partir de la famosa pirámide de Cohn para pruebas automatizadas funcionales, y te servirá de referencia para mejorar tu estrategia holística de pruebas de performance.

Por Federico Toledo (Abstracta) y Leandro Melendez (Grafana k6)
Las automatizaciones de diversos tipos de pruebas de software han generado grandes beneficios, tales como la mejora de la eficiencia, la reducción de errores humanos, la aceleración de procesos de pruebas, reducción de costos, y mayor cobertura.
En definitiva, han revolucionado la forma en que abordamos el control de calidad en el desarrollo de software.
Dentro de las pruebas que es necesario automatizar, las de carga se destacan por su importancia en ayudarnos a preparar los sistemas para momentos críticos, de alta demanda. Nos permiten comprender cómo se comportan al ser accedidos por muchas personas de manera concurrente, y así prevenir posibles problemas de rendimiento.
En contextos ágiles, donde las aplicaciones están en constante evolución, es esencial subrayar la importancia del mantenimiento de scripts de pruebas automatizadas de performance.
Los sistemas que probamos evolucionan y cambian a medida que ejecutamos las pruebas de performance durante las iteraciones de desarrollo. Por ello, las nuevas funcionalidades se liberarán a testing regularmente, requiriendo nuevas pruebas, así como la ejecución de las existentes.
Esto llevará a que el código de pruebas tenga que ser mantenido de igual forma que el código de la aplicación.
Es entonces cuando entra en juego la automatización de pruebas de performance, en consideración de distintos aspectos, tales como su facilidad de preparación, su mantenibilidad, posibilidad de ejecución recurrente, etc.
Aun así, también encontramos algunas de las mismas desventajas de la automatización funcional en las pruebas de performance, cuando no se siguen las buenas prácticas. Hay aspectos que es importante tener en cuenta para crear automatización de calidad.
Si no diseñamos y organizamos nuestras automatizaciones adecuadamente, pueden llegar a ser contraproducentes, ya que nos llevará más costo el mantenimiento que el beneficio de contar con esas pruebas.
¿Cómo automatizar pruebas de performance de manera eficiente?
El modelo de la pirámide de automatización, o “Pirámide Azteca de Sacrificios de la Automatización” (como la llama Leandro), nos ofrece lineamientos para que los equipos optimicen los esfuerzos y resultados que obtienen de sus pruebas automatizadas, tanto las funcionales como las de performance.
Esta estrategia es útil tanto para cuando se abordan las pruebas de performance en metodologías waterfall como en metodologías ágiles.
A continuación, compartimos un modelo que puede servir para guiar el momento de definir una estrategia de pruebas de performance.
El modelo de la pirámide aplicado a performance
A partir de la famosa pirámide de Cohn para pruebas automatizadas funcionales, ambos (tanto Leandro como Federico) coincidimos en que el modelo, tal como se explica con el triángulo como una pirámide, aplica a las pruebas de performance.
Este modelo ofrece pautas sobre la priorización de los tipos de automatización. ¿Cómo lo hace? Si bien hay distintas versiones e interpretaciones, en general indica que se debe dar una mayor prioridad y abundancia a las automatizaciones a nivel unitario. Luego, a las pruebas de integración (o de API o servicios) y, en una categoría de menor prioridad, las automatizaciones a nivel de Front End o GUI (del inglés, interfaz gráfica de usuario), que llamaremos end-to-end, ya que prueban todo el sistema de punta a punta.
En la siguiente imagen, mostramos las equivalencias entre el modelo de Cohn y el de la pirámide de performance. En ella, podemos ver claramente qué correspondería a cada nivel.
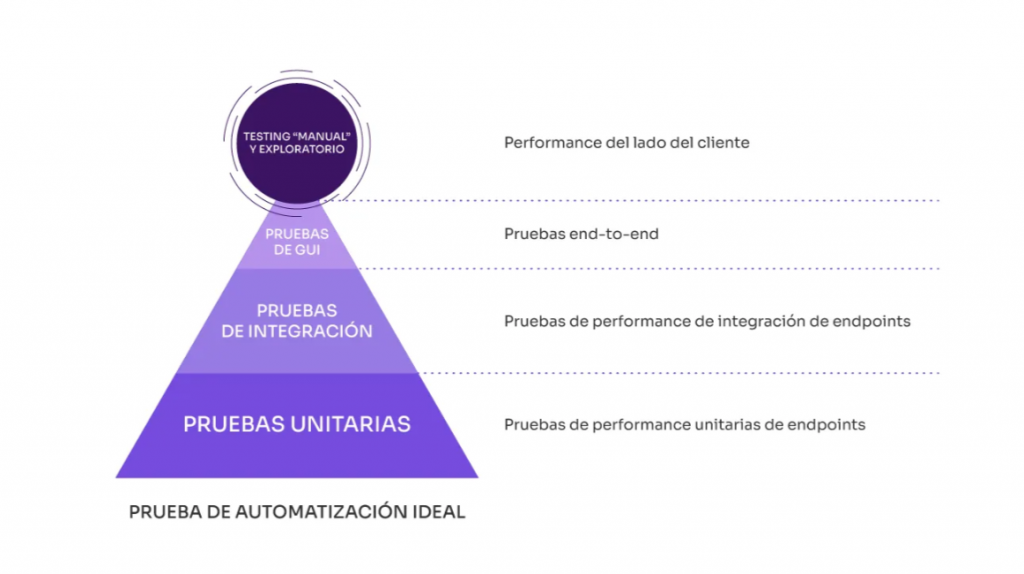
A continuación, observamos cuáles son las ventajas y desventajas de cada capa. A medida que bajamos por la pirámide hacia la base, podemos obtener:
- Pruebas de API y unitarias más baratas: más fáciles de preparar, con menos infraestructura.
- Más fácil de mantener para que pueda correr con más frecuencia (todos los días)
- Las pruebas pueden realizarse antes.
- Desventajas: no son concluyentes sobre las métricas reales de la experiencia de usuario.
Y a medida que subimos por la pirámide, encontramos:
- Escenarios de carga que requieren infraestructura y carga similares a los de producción.
- Pruebas más caras porque son más difíciles de preparar y mantener.
- Mejores resultados, correspondencia directa con las métricas de personas usando E2E.
Más adelante, en este mismo artículo, entraremos más en detalle en cada uno de los niveles de la pirámide.
Como el modelo está basado en una pirámide, Leandro le llama “la pirámide azteca de sacrificios de la automatización”.
¿Por qué mencionar ‘sacrificios’? Esto se relaciona con la idea de que, al igual que en la época de los aztecas, los sacrificios se llevan a cabo en la cima de la pirámide.
Llevándolo al software, es aquí donde la mayoría intenta automatizar en exceso, pruebas tipo end-to-end, lo cual puede verse como un sacrificio.
Lamentablemente, lo común es ver que las organizaciones o equipos tengan una estrategia en la cual las cantidades de automatizaciones, o la cobertura, sean opuestos a lo que plantea la pirámide. A este antipatrón se lo conoce comúnmente como el modelo del cono de helado. Pero que debido a ello Leandro le llama el cono de los sacrificios.
La estrategia planteada por la pirámide indica que se deberían priorizar las automatizaciones unitarias, luego las pruebas de integración y, por último, minimizar los sacrificios en la cima con automatizaciones end-to-end, en lugar de estar generando conos de sacrificios.
Pirámide para las pruebas de performance, cada capa al detalle
La idea de esta pirámide es que sirva como referencia al momento de establecer la estrategia de pruebas del sistema en cuanto a performance. Esto será más o menos aplicable dependiendo de la arquitectura. Podemos decir que es más que nada aplicable cuando hay microservicios, o al menos una capa de servicios SOAP o REST.
A continuación, veremos más en profundidad y detalle los aspectos de cada una de las capas que mencionamos del modelo.
Comenzaremos por la base, en la cual encontraremos las pruebas unitarias de performance. Luego, describiremos las pruebas de integración de los servicios, las pruebas end-to-end, Por último, aspectos de performance del lado del cliente.
Pruebas de performance unitarias
El objetivo es probar individualmente cada uno de los servicios de forma aislada simulando cierta carga sobre el mismo. Preparar una prueba es sumamente simple ya que se trata de un solo pedido HTTP.
Aquí, ejecutaremos siempre la misma prueba y compararemos los resultados más recientes con los anteriores, para observar si los tiempos de respuesta muestran alguna degradación significativa, con el fin de identificar y monitorear posibles problemas de rendimiento en el sistema.
Cuando hablamos de pruebas end-to-end en la simulación de carga, nuestro escenario de carga y las aserciones se basan en los objetivos del negocio.
¿Cuántos usuarios simulo cuando realizamos pruebas a nivel de servicios? En especial cuando esas pruebas serán ejecutadas en un entorno de pruebas reducido. Las pruebas deben tener criterios de aceptación (aserciones) lo más ajustados posible, de modo que, ante la menor degradación en la performance de esa funcionalidad y antes de cualquier impacto negativo, una validación falle y señale el problema.
Por lo general, esto se logra verificando tasas de error, tiempos de respuesta y throughput (cantidad de solicitudes o requisitos atendidos por segundo).
En los siguientes gráficos, compartimos un problema típico que queremos evitar:
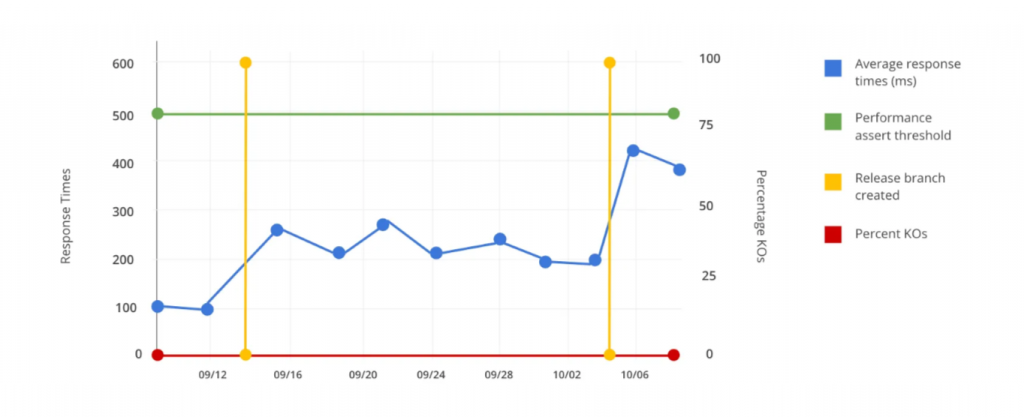
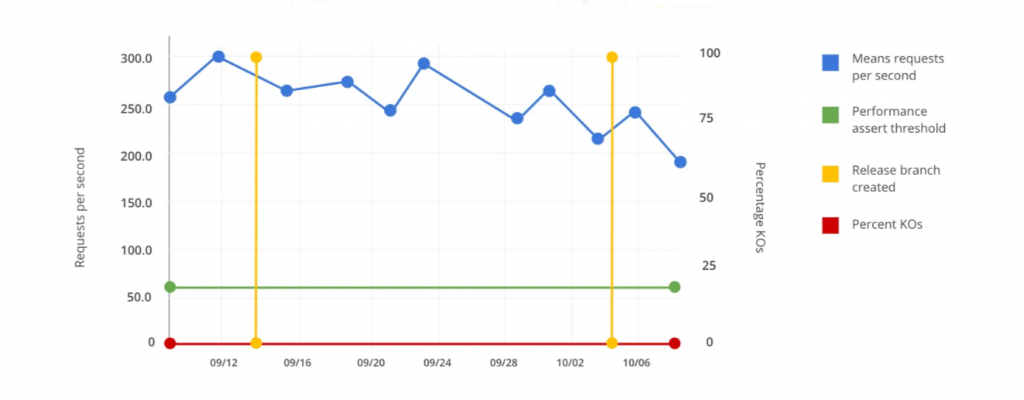
En la primera imagen, observamos que los tiempos de respuesta aumentan. En el segundo, notamos una disminución en los requisitos por segundo (RPS), pero la prueba no reporta un error ni brinda una alerta sobre esta degradación porque los criterios de aceptación son poco rigurosos. La prueba está verificando que el rendimiento sea superior a 60 RPS, por lo que cuando la funcionalidad disminuye de 250 a 200, nadie prestará atención a eso.
Necesitamos que las aserciones sean más rigurosas para que una degradación de este tipo haga que el pipeline falle.
Entonces, para evitar estos problemas, veamos cómo definir la carga y las aserciones.
Lo que necesitamos hacer es realizar ciertas ejecuciones en modo experimental, para poder determinar la carga y aserciones que configuraremos en nuestras pruebas unitarias de performance, con el fin de ejecutarlas de manera continua en nuestro pipeline.
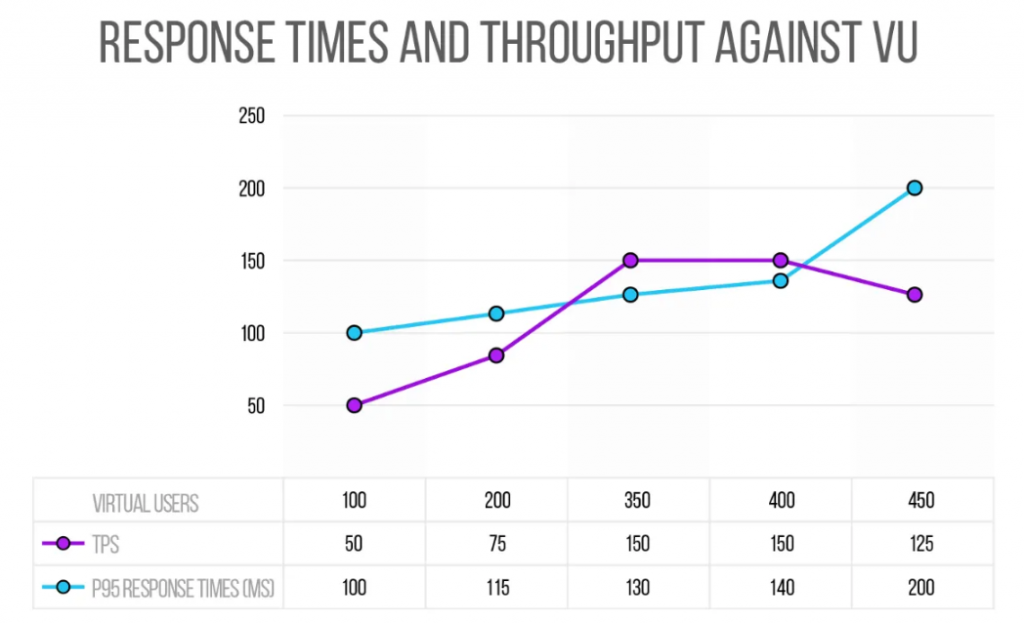
Digamos que realizamos una primera prueba con 100 ejecuciones paralelas que resulta sin errores, los tiempos de respuesta son inferiores a 100 milisegundos (ms),al menos el percentil 95, y el throughput es de 50 RPS.
A continuación, ejecutamos la misma prueba pero con 200 RPS. Nuevamente, no se producen errores y los tiempos se sitúan en 115 ms y el rendimiento en 75 RPS.
Genial, está escalando.
Si seguimos por este camino de pruebas, en algún momento llegaremos a una carga determinada en la que veremos que ya no conseguimos aumentar el throughput.
Siguiendo este escenario, imaginemos que llegamos a 350 ejecuciones en paralelo y tenemos un throughput de 150 RPS, con tiempos de respuesta de 130 ms y 0% de errores.
Si pasamos de 400, el throughput sigue siendo de unos 150 RPS, y con 450 en paralelo el throughput es incluso inferior a 150.
Hay un concepto llamado Knee point (rodilla, por el quiebre en la gráfica) con el que nos encontraríamos en cierto punto, el cual determina que saturamos algún cuello de botella.
Se espera que el número de requisitos por segundo aumente cuando incrementemos el número de ejecuciones concurrentes. Si no ocurre, es porque estamos sobrecargando la capacidad del sistema.
Este es el método básico para encontrar el Knee point al hacer pruebas de estrés, cuando queremos saber cuánto pueden escalar nuestros servidores bajo la configuración actual.
Así, al final de este experimento, llegamos a definir el escenario que queremos incluir en nuestro pipeline, con las siguientes aserciones:
Carga: 350 ejecuciones concurrentes.
Aserciones:
- Menos de 1% de error.
- Tiempos de respuesta P95 <130 ms + 10%.
- Throughput >= 150 RPS — 10%.
A continuación, la prueba que programaremos para que siga ejecutándose con frecuencia es la que ejecuta 350 ejecuciones concurrentes. Esperamos que tenga menos de un 1% de error con tiempos de respuesta por debajo de 130 ms, con un posible margen del 10%, tal vez un 20%,
Por último, pero no menos importante, tenemos que verificar que el throughput sea al menos 150 RPS, también con un margen del 10%.
Así, podemos detectar lo antes posible cuando un cambio hace que disminuya el rendimiento del sistema.
Para que todo esto sea válido, necesitamos un entorno exclusivo para las pruebas. De esa manera, los resultados se vuelven más predecibles y no se ven afectados por factores como la ejecución simultánea de otras tareas por parte de otras personas.
Pruebas de rendimiento de integración
En estas pruebas, vamos a poder probar varios servicios a la vez para ver cómo afectan la performance unos a otros. Para esto, tomaremos las mismas pruebas unitarias y las combinaremos en un único escenario concurrente. Si ya tenemos las otras preparadas, armar estas pruebas no debería ser tan complejo.
Antes de continuar, nos gustaría aclarar por qué es importante probar los mismos servicios de forma combinada.
“Falacia de la composición”
Probar las partes no basta para saber cómo se comportará el conjunto.
Hay que probar el conjunto para ver cómo interactúan las partes.
Tal como nos enseñó Jerry Weinberg, los buenos equipos de testing saben que no es suficiente probar las “partes” para saber cómo se comportará el “todo”, ya que hay que probar el todo para ver cómo interactúan las partes.
Por lo tanto, deberíamos complementar las pruebas unitarias con pruebas de integración.
Pruebas de performance end-to-end
Estas son las clásicas pruebas de performance en las cuales simulamos la carga que esperamos en el sistema (cierta cantidad de personas accediendo en forma concurrente) en un entorno que replica las condiciones del entorno de producción. Los scripts se deben preparar a nivel de comunicación del cliente (browser, app mobile, etc) y no a nivel de servicios.
El objetivo principal de las pruebas end-to-end de performance es identificar posibles cuellos de botella, problemas de escalabilidad o degradación del rendimiento que puedan surgir en situaciones de uso real.
Estas pruebas suelen involucrar la simulación de personas reales interactuando con la aplicación a través de múltiples pasos, como navegar por páginas, completar formularios y realizar transacciones. La recopilación de datos sobre tiempos de respuesta, tasas de error y otros indicadores clave de rendimiento es esencial para evaluar el comportamiento del sistema bajo carga.
Son, en definitiva, una parte fundamental del proceso de aseguramiento de la calidad, ya que ayudan a que una aplicación funcione de manera eficiente y efectiva en condiciones de producción, y minimizar así los problemas de performance.
Performance del lado del cliente
Además de las capas anteriores de la pirámide, que se centran en el lado de los servidores, nos gustaría recordarte la relevancia de nunca olvidarse del cliente. Problemas en el lado del cliente que generen demoras en la experiencia final, pueden invalidar los esfuerzos de optimización realizados en el backend (los servidores).
En el caso de aplicaciones web, existen numerosas herramientas disponibles para evaluar la performance desde esta perspectiva. No solo te indicarán automáticamente qué issues hay presentes en el sitio, sino que te mostrarán cómo resolverlos. Compartimos algunas de ellas:
- Lighthouse, como parte de las Google Chrome Developer Tools
- Google PageSpeed Insights
- Website.io
- Yslow
En el caso de Mobile apps, recomendamos utilizar Apptim, una herramienta que se especializa en la evaluación de la performance de aplicaciones móviles.
Estas herramientas pueden ser de gran utilidad para ayudar a que tu aplicación funcione de manera eficiente y ofrezca una experiencia óptima.
Además, es importante mencionar que existe la posibilidad de realizar pruebas híbridas, como lo propuesto por Marie Cruz en su artículo sobre pruebas de performance web. Esta estrategia combina herramientas como k6 browser y Google Lighthouse para obtener una visión completa de la performance de tu aplicación desde diferentes perspectivas.
La propuesta de pruebas híbridas puede ser especialmente beneficiosa para identificar problemas tanto en el lado del servidor como en el lado del cliente.
Otras vistas del modelo de la pirámide
Algo que tienen de bueno los modelos, es que permiten analizar distintas vistas que pueden resultar útiles. Además de lo ya planteado anteriormente, queremos compartir otros aspectos interesantes al analizar el mismo modelo, lo cual le da más dimensiones para considerar.
Frecuencia de ejecuciones
Imaginemos otra vista de la pirámide, la cual se refiere a la frecuencia de las ejecuciones que se deben efectuar en cada nivel de pruebas. Esto es especialmente importante en proyectos modernos que siguen metodologías ágiles, continuas, o variaciones del estilo ágil.
Lo fundamental de esto es determinar qué tan frecuente puedo ejecutar cada tipo de pruebas. Esto depende de qué tan fácil de preparar, codificar, y mantener son esas pruebas, así como, por otro lado, qué información me aportan.
Por ello, la propuesta es ejecutar las pruebas unitarias de los servicios frecuentemente, quizá en cada build del pipeline, tal como quedó explicado (por Federico) en este webinar y en este post.
Para ver cómo impactan los servicios unos sobre otros, de vez en cuando deberíamos ejecutar pruebas donde combinemos varios servicios, a lo que estamos llamando como pruebas de integración.
Como hasta acá no sabemos nada sobre cómo será la experiencia de usuario, tenemos que complementar esto con las pruebas clásicas de carga. Son mucho más complicadas de preparar, pero son las únicas que nos ayudan a reducir estos riesgos.
Lo bueno es que si ya hicimos pruebas unitarias y pruebas de integración de manera frecuente, seguramente podemos llegar a esta etapa con menos probabilidad de encontrar problemas serios o, al menos, ya nos adelantamos a varios de ellos.
Similar a lo explicado con la anterior pirámide, muchas organizaciones siguen una estrategia inversa y se enfocan en ejecutar más seguido las pruebas de carga mientras realizan cantidades muy bajas y ejecutan con poca frecuencia las pruebas unitarias.
Infraestructura de pruebas de performance
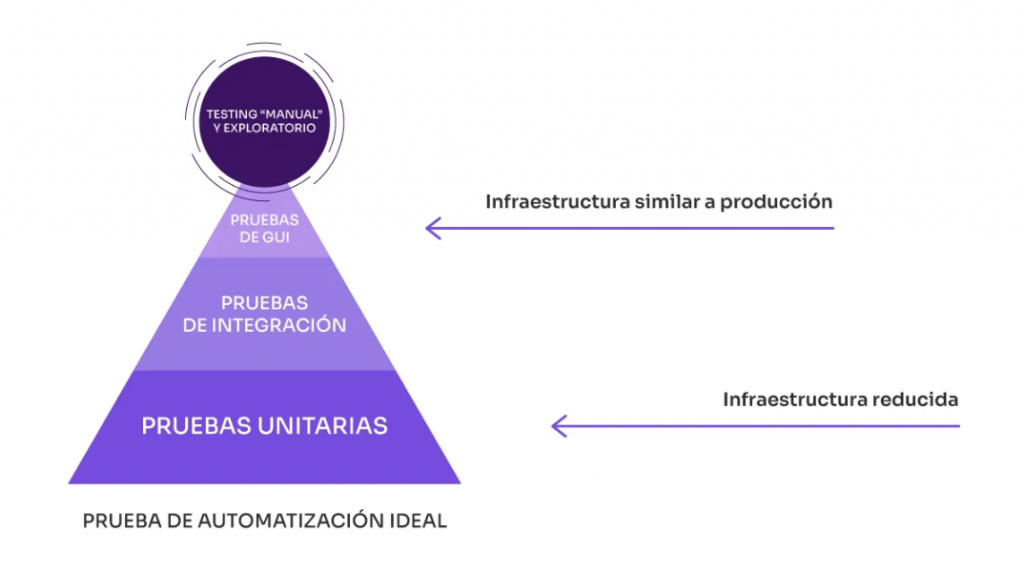
¿Cuántas veces escucharon ustedes también que solo podemos ejecutar pruebas de performance sobre infraestructura que sea muy similar a la de producción?
Esta afirmación creemos que aplica más que nada a las pruebas que corresponden a la capa más alta de la pirámide, o sea, a las pruebas end-to-end que nos permitirán conocer los tiempos de respuesta que obtendrán quienes accedan al sistema.
Por otra parte, vale aclarar que podemos ejecutar pruebas de performance en infraestructuras de menor potencia, como podrán ser los entornos de testing o desarrollo, y sacar resultados muy aprovechables de esas ejecuciones.
Lo que hay que tener bien presente es que los resultados no se deberían extrapolar. En otras palabras, si ejecuto en un entorno de pruebas, no es seguro asumir que en producción, donde la infraestructura tiene el doble de poder, los tiempos de respuesta se reducirán a la mitad.
Ejecutar pruebas a nivel unitario y de integración en entornos reducidos como los de pruebas o desarrollo, trae muchas ventajas. Hay errores y optimizaciones que pueden ser atacados a pesar de no contar con ambientes como producción.
Las pruebas de performance siempre arrojan resultados valiosos en todos los escenarios.
En particular, la ventaja de ejecutar estas pruebas en entornos reducidos (scaled down) es que vamos a poder estresar al sistema, para analizar cómo se comporta cerca de sus límites, con cargas menores. Esto implica menos costos de infraestructura de pruebas o de licencia de herramientas de simulación de carga. La preparación y gestión será más fácil y los resultados podrán obtenerse más temprano.
Por otro lado, si el ambiente de pruebas es similar a producción, la ventaja es que vamos a poder analizar más problemas, o problemas más parecidos a los que tendremos en producción.
¿Aplicarías el modelo de la pirámide en tus pruebas de performance?
¿Qué te pareció este tópico? ¿Qué opinas de la pirámide de automatización aplicada a performance? ¿Tienes otros tips o ideas al respecto para compartir? ¡Nos gustaría conocer tu opinión y experiencia!

¡Síguenos en LinkedIn, X, Facebook, Instagram y YouTube para ser parte de nuestra comunidad!
Contenidos relacionados

Auto Playwright: transformando la automatización de pruebas con IA
¿Cómo utilizar Auto Playwright? ¿Es posible mejorar la eficiencia en el desarrollo de pruebas con esta herramienta con apoyo en Inteligencia Artificial? En este artículo, compartimos pruebas y casos de uso reales para poder responderte estas preguntas con todos los detalles.

Historia del WOPR: una mirada desde adentro
¿Cómo nació el “Workshop on Performance and Reliability” (WOPR)? ¿Cuál es la visión que hay detrás? Descubrilo en este artículo, con entrevistas a Eric Proegler y Paul Holland.



{kind=link}
{kind=link}